
Appendix was added on the 14th of Febuary 2018, in response to comments made to me on twitter. In this connection “retpoline pause lfence” and “retpoline ud2” was added to the table. Other than that only typos where fixed since original post.
Abstract
In this blog post I explore the Retpoline mitigation that Paul Turner of Google suggested for the Spectre indirect branch variant issue [1]. A short differential side channel analysis is made along with a performance analysis. The impact of the use of a pause instruction in retpoline is discussed. Finally I consider the technical debt leveraged on CPU developers of a widely deployed retpoline.
How does retpoline work
This section follows the google presentation of retpoline closely [1]. I included it because it provides the context for the remainder of this blog post. A jmp rax is turned into the following code:
- call set_up_target;
- capture_spec:
- pause;
- jmp capture_spec
- set_up_target:
- mov [rsp],rax
- ret;
call set_up_target (1) pushes the address of capture_spec(2) to the return stack buffer (RSB, cpu internal buffer used to predict returns). It also pushes the address of capture_spec(2) to the program stack and transfers control to set_up_target (5). The mov [rsp],rax overwrites the return stack address on the program stack, so that any subsequent returns will pop the stack and return to the original target in its architectural path. The speculative path of the return remains the value from the RSB and thus the CPU will speculatively execute the code starting at (2). The pause instruction is meant to relinquish pipeline resources to co-located hyperthreads and save power if no co-located hyperthreads are present. The jmp in line 4 continues to repeat the pause until the speculative execution is rolled back when the ret in line 7 finished executing.
In simple terms this means the speculative path will resolve to a spinlock thus not leak any information through a side channel. The architectural path will eventually resolve correctly and the program will run as it is supposed to.
Side channel analysis of retpoline
Retpoline’s architectural side channels consist of flushing an entry in the RSB caused by the call in line (1). This information is unlikely to bring an attacker much advantage and would require an attack to have a sufficient amount of control of the RSB. The 6th line makes a store access on the stack. This is visible through a cache side channel to an attacker — provided the attack has sufficient control. However, it is unlikely to provide much information given that the stack is usually used by the functions themselves. It is worth noting that any information this side channel can provide is also provided by the jmp rax (6). Presumably retpoline’s stack access provides slightly less information to an attacker than the original jmp rax instruction – i.e. BTB indexing bits vs. cache set indexing bits. The 7th line is more tricky: if the CPU updates the BTB after a misprediction, the BTB side channel will be similar useful to the original jmp rax. I think it is likely that the BTB is not updated until retirement, so that this side channel isn’t present. Since the pause instruction (line 3) is a CPU hint, the CPU may choose to take or ignore the hint at its discretion – more on this below. Thus, pause may or may not provide a side channel. If external power is plugged in and the hint is taken one can see a co-located hyperthread speed up (see [2]), which is the purpose of having the pause instruction here, but certainly a side channel as well. If the CPU is running in power saving mode (e.g. unplugged laptop), pausing provides a side channel since executing a pause instruction on two co-located hardware threads causes a delay for both, presumably through C-State interaction. See[3]. In sum, I think the side channels provided by retpoline is less valuable than the side channel provided by the original indirect branch (but is still present).
Performance analysis of retpoline
A jmp rax instruction takes about 4 clock cycles to execute and predicts correctly very often. It is replaced in retpoline with a ret instruction which will always mispredict and thus executes far slower. However, unlike doing hard serialization once the ret instruction has been executed out-of-order, the CPU seems to be able to continue without a pipeline flush and thus allowing out-of-order execution to continue. This creates two corner cases: firstly, where dependencies block out-of-order execution across the indirect branch, and secondly, when there is no dependence across the indirect branch. I managed to create a sequence of instructions where retpoline was just as fast as the original unpredicted branch – this is the case when the instructions after the branch depend on the results of the instructions before the branch. Obviously, any co-located hyperthread will be more affected by the retpoline than a predicted indirect branch, but the thread itself does not lose any cycles. At first this seems weird, but imagine completely dependant ALU integer instructions on both sides of the indirect branch – with the branch unit being completely free, both retpoline and the indirect branch will execute concurrently with the integer ALU instructions before the branch. Since the integer ALU instructions after the branch are dependant of those before the branch, they only get scheduled for execution once all prior instructions have been executed. Thus, retpoline and an indirect branch perform equally. In the case of no dependencies across the indirect branch, retpoline is slower. Retpoline will not allow the out-of-order execution to continue until the ret instruction is executed and consequently adding a penalty compared to a predicted indirect branch. In general, the longer it takes for the indirect branch to resolve, the higher the penalty of retpoline is. There is also an indirect performance cost of retpoline which – in my opinion – is likely to be somewhat smaller. The call in line 1 will push a return address onto the RSB (and consequently may evict the oldest entry in the RSB), and thus potentially causing an RSB underflow once a previous call returns. A RSB underflow will manifest itself as a negative performance impact if the evicted RSB entry causes mispredictions or stalls in unrelated code later on. For this to happen a call stack is required to be deeper than the the size of the RSB. The stall penalty of the underflow was big enough to cause Intel to add prediction to the microarchitecture (for Broadwell and Skylake). If this prediction was as efficient as using the RSB, the RSB would not exist.
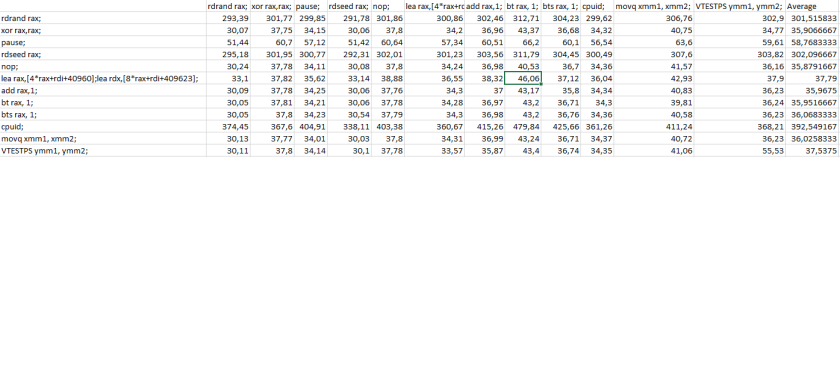
The following table presents the results of my micro benchmarking:
| Unit Clock cycles | Mean | Std.dev | Median |
| jmp rsi | 350.33 | 95.48 | 346 |
| retpoline pause | 410.64 | 65,94 | 410 |
| retpoline lfence | 403.76 | 25,96 | 404 |
| retpoline clean | 402.13 | 19,99 | 402 |
| retpoline pause lfence | 406.74 | 64,76 | 404 |
| retpoline ud2 | 404,29 | 28,70 | 402 |
The “retpoline clean” is without the pause instruction, “retpoline lfence” is where pause has been replaced with a lfence instruction. The results are generally not very stable over multiple runs but with all three versions of retpoline often ending up with an average of around 400-410 cycles and the indirect branch being around 50 clks faster on average. Thus, some additional care should be taken before concluding
that “retpoline pause” is slower than the others. I ran the tests with 100k observations and removed the slowest 10% observations in a primitive noise reduction approach. The microbenchmark is for a bad case with no dependency across the indirect branch for integer instructions (add rsi,1, add rbx, 1 respectively) and is run on a Intel i7-6700k. While microbenchmarking is important for the arguments I will put forth in this text, it is important to note that they are not reflective on the system’s performance as the incidence of indirect branches is relatively small and this benchmark is manufactured to portrait cases which are worse than in normal scenarios. Also, the microbenchmarking completely ignores any indirect effects.
The weird case of pause
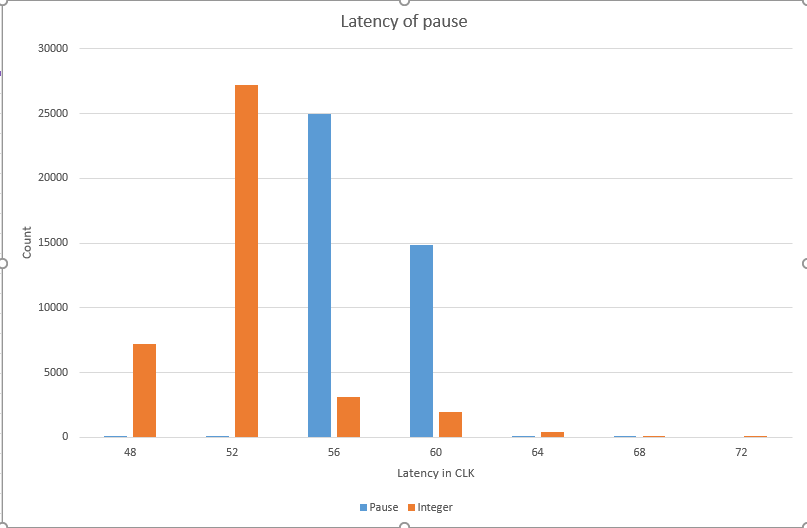
It immediately seemed weird to me to have the pause instruction in the spinlock in line 3 of retpoline. Usually we have pause instructions in spinlocks, but spinlocks execute architecturally at some point. Having a pause of 10 clock cycles for Broadwell and 100 for Skylake in the spinlock potentially causes the CPU to pause the architectural flow that needs to be done before the return instruction can be executed. This may lead to a larger-than-necessary penalty to the spinlock. However, pause is not actually an instruction. It is a hint to the CPU and my guess is that the hint is not taken. I ran retpoline on my Broadwell and my Skylake and compared the penalty: there was almost no difference. This is important because we would expect the different implementation of pause to give different average latencies if it was actually executed (10 clk vs 100 clk). Another argument for pause not being executed speculatively is that pausing is connected to a VmExit. I can only guess why Intel made it is possible to get a VmExit on pause instruction. I think the most compelling reason would be to use the pause used by spinlock in a guest to process small work items in the hypervisor instead of just idling the CPU. This would probably also help virtualizing hardware. If I am right about this, it would be sensible for the pause hint actually pause only on retirement instead of pausing the CPU speculatively. Another argument is power management: the behavior of the pause instruction depends on the C-State of a co-located hyperthread. Presumably this gives us one of the two side channels as described in a previous section. There is little reason on why a CPU designer would pause a thread which is executing other instructions out-of-order.
Discussion of technical debt of retpoline
As clever as retpoline seems, I think it is fundamentally broken. Not because it does not work but instead because it builds a large amount of technical debt. Adding retpoline to a piece of software would require CPU designers to make sure that legacy software is compatible with new CPUs. If a company like Google applies retpoline in their instructure it is fairly unproblematic, Google has a nice inventory of software running on their systems and they can make sure that software applied to new CPUs is recompiled and consequently this poses no constraints on a CPU designer. However, if we add retpoline to a compiler we can be sure it will be added to all kinds of software including virtual machines, containers, specialized software etc. These pieces of software often do not remain supported, they are poorly catalogued and consequently, if the behavior of retpoline changes significantly, these systems may perform suboptimal, be unsafe or even completely break. This effectively ties the hands of CPU designers as they strive to improve the CPU in the future.
The first concrete problem I see is the use of the pause hint: regardless of whether the pause hint is taken in retpoline or not, its non-intended use in retpoline ties the behavior of this instruction down for CPU designers in future generations of CPUs. It is worth noting here that we have at least 3 different implementations of the pause hint in different CPUs already (treated as nop, stall 10 clks, stall 100 clks)[5]. Adding to that the complexity of the instruction I outlined above, it would be fair to assume that this instruction might need changes in future generations of CPUs. Thus, having the pause hint in retpoline in scattered over software everywhere might turn out to be a bad idea thinking long term. The good news here is that there probably is a good solution for this. Replacing the pause instruction with lfence will serialize the speculative path and probably even stop it from looping; effectively stopping the execution of the spinlock may free up resources for co-located hyperthread as well as branch execution units for the main thread that otherwise would have been tied up by the jmp instruction in line 4. I ran some test on Skylake and found very near identical performance results for pause and lfence, suggesting that this is viable solution. It is important to note that the lfence instruction was previously documented to only serialize loads. But instead it silently serialized all instructions — which is now the documented behavior since Intel published their errata documents for the Spectre/Meltdown patches [7]. So, the mortgage on lfence is small and has already been signed.
The second concrete problem I see is the construct which repoline uses to direct speculative execution into the spinlock is a much bigger problem. On Skylake, return instructions predict by using the indirect branch predictor, requiring Skylake to be handled differently than other CPUs. The problem is twofold: on the one hand, the very common ret instruction needs to be replaced with retpoline (or other non-speculative branching), and on the other hand, the hardware interrupt raised in line 6 may underflow the RSB in the interrupt handler. Thus, repoline is already potentially unsafe on some CPUs (in my opinion much less than without retpolinie though). The technical debt here is that retpoline may be completely unsafe if future CPUs stop relying on the RSB for return prediction. There may be many reasons for a CPU designer to change this. For example a completely unified system for indirect branches or prediction of monotonic returns (returns with only one return address). The latter will keep the RSB save from non-monotonic returns if the RSB underflows and thus may perform better when there are deep call stacks. I do not know whether these things are good ideas, but retpoline might effectively rule them out. Also, one could imagine conflicts with future CPU-based control-flow integrity systems, etc.
One could argue that performance optimization rely on microarchitecture details all the time, but there is an important difference between breaking a performance optimization and a security patch. Already we see problems with updating broken libraries amongst software vendors, it’s not difficult to imagine what would happen if a secure software becomes insecure because of CPU evolution.
Instead of taking on technical debt potentially forever, I suggest we use either a less secure option (i.e. lfence ahead of indirect branches) or a more expensive option such as IPBP [7] or replacing indirect calls with iret (which is documented to be serializing). That constitutes a high price now, but avoids paying rent on technical debts in perpetuity.
Conclusion
Retpoline is an effective mitigation for Spectre variants which rely on causing misprediction on indirect branches on some CPUs. From a pure side channel perspective retpoline adds a different side channel but it is an improvement over the side channel of a traditional indirect branch nonetheless. Retpoline’s performance penalty is complex, but likely smaller than the penalty of the serializing alternatives. However, as Retpoline relies on assumptions about the underlying microarchitecture, it adds technical debt if used widely. If Google, Microsoft or whoever with software-deployment management wants to use it, they have my blessing but there is reasons for scepticism if it is a good idea to have it in general purpose compilers. CPU Vendor’s short term marketing deficits should not lead us to trade small short term performance gains causing technical debt to be paid back with interest in the future for a more complex microarchitecture.
Appendix added 14th of Febuary 2018
Stephen Checkoway of University of Illinois at Chicago commented that it might be worth testing an ud2 instruction in the speculative executed spinlock. I find this idea promising because ud2 essentially just throws an “invalid opcode” exception and thus abusing it for retpoline is likely to produce equivalent performance to that of lfence, perhaps even better, Further, it’s unlikely that using this instruction is associated with any technical debt. The simple test result here shows that the direct performance impact is approximately similar (see table above) that of the other versions of the spinlock.
Some implemented versions of retpoline uses a pause followed by an lfence instruction. I added this to the performance table as well. Thanks to Khun Selom & @ed_maste (twitter account).
Literature
[1] Turner, Paul. “Retpoline”. https://support.google.com/faqs/answer/7625886
[2] Fogh, Anders. “Two covert channels”. https://cyber.wtf/2016/08/01/two-covert-channels/
[3] Fogh, Anders “Covert Shotgun”. https://cyber.wtf/2016/09/27/covert-shotgun/
[4]Intel, “Intel® 64 and IA-32 Architectures Software Developer Manual: Vol 3”
[5] Intel. Intel® 64 and IA-32 Architectures Optimization Reference Manual. July 2017. https://software.intel.com/sites/default/files/managed/9e/bc/64-ia-32-architectures-optimization-manual.pdf
[6] Evtyushkin, Dmitry, Dmitry Ponomarev, and Nael Abu-Ghazaleh. “Jump over ASLR: Attacking branch predictors to bypass ASLR.” Microarchitecture (MICRO), 2016 49th Annual IEEE/ACM International Symposium on. IEEE, 2016.
[7] Intel, “Speculative Execution and Indirect Branch Prediction Side Channel Analysis Method”, https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00088&languageid=en-fr


You must be logged in to post a comment.