
Welcome back, still on it? This is part 3 of our blog series, if you’re curious about part 1 and 2, please check them out here and here. This time I’m happy to introduce a set of borderline funny findings and tackle one of the hypotheses we put together for Raphael Vinot’s and my talk “The Kings In Your Castle”, presented at this year’s Troopers Conference in Heidelberg. I will discuss our findings regarding exploits present in known targeted attacks, the obstacles we faced during analysis and how we worked our way around. So, sit back, relax, here we go.
Curiosities
As you might be aware of, most data sets come with information, as well as most show one or another curiosity. Finding curiosities means learning literally unexpected things, which is why researchers jump at those with the passion of a hungry wolf. Thus, let me start the list of our findings with a curiosity.
While performing clustering on ssdeep hashes we found something we dubbed sddeep collisions, due to lack of better naming. Ssdeep is a program for computing context triggered piecewise hashes. These so called fuzzy hashes, as opposed to cryptographic hashes, do not uniquely identify a given data blob. They are calculated piecewise and are able to identify shared byte sequences among two targets. They are frequently used to ‘describe’ malicious binaries, in order to be able to match with similar binaries and eventually find groups of malware samples or even identify malware families.
The nature of piecewise hashes though implies, that hashes of two binaries cannot be identical, if the binaries show differences. Hence, it is a curious finding, that a number of unique samples within our set showed identical ssdeep hashes. Without spending too much time picking at the implementation of the fuzzy hashing algorithm itself, we assume that ssdeep does not consider the entire binary for hashing. We found a case, where 5 MB of empty padding were no reason for ssdeep to show any difference in the resulting fuzzy hash.
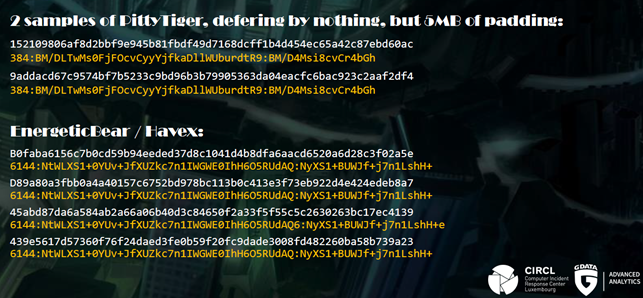
More than padding, ssdeep on some occasions indeed missed significant differences in the data sections of compared binaries. Given that analysts and corporations use ssdeep in work benches and production systems we found it worth a mention, that identical fuzzy hashes do by no means proof, that the compared binaries are identical.

We learned another curiosity when randomly staring at the gathered data. It is fascinating how the human eye manages to find patterns, and indeed very instructive before starting to implement queries or planning for application of machine learning. This way we saw, that for example compilation timestamps of binaries usually follow lose patterns within an event. A number of events though show outliers when it comes to timestamps; such as a binary compiled in 1996 while others are compiled post-2007, or a binary with a stamp from 2036. Of course, such outliers can have multiple explanations. Ones that come to mind the fastest are either the timestamps are falsified, the attackers forgot to falsify all timestamps, the campaign made use of readily compiled (old) tools, or maybe a runtime packer was used which falsifies the timestamps without explicit intention of the attackers.
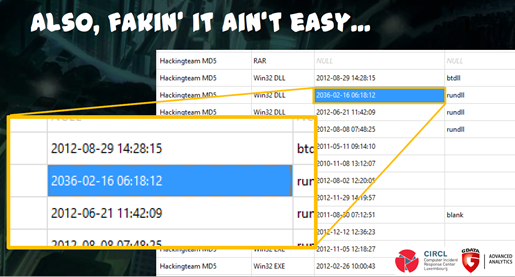
One conclusion though lies at hand. To freely quote a splendid APT researcher, attackers learn just like we do and improve over time, which implies that they might have made more mistakes in the past. Thus, by analyzing historical data about a campaign or group one might be able to learn unexpected tidbits. Moreover, by looking at things learned by the attacker as in changes in malware and intrusion techniques, one might gather insights about obstacles the attackers faced in the past. Adoption of a runtime packer or adding of a stealth module to a given RAT might expose, that the attacker’s tools at some point were detected by security software.
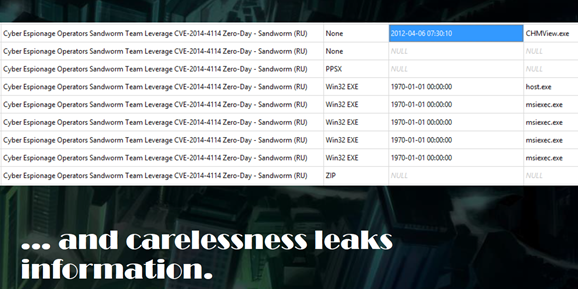
OMFG!! They used e.x.p.l.o.i.t.s.!!1!
Like in real life, humans tend to conclude that a digital attack, which caused big damage, naturally came with big power. In the world of cyber though, this equation has a lot of unknowns. In fact, the success of an attack and the damage it can cause are influenced by many factors, that are independent of an attacker’s capabilities and wealth. While not true in all cases, mostly, the possession of one or more 0-days involves some level of resources or at least explicit know-how combined with engineering time.
This leads to a natural assumption: Folks who do APTs involving 0-days must be either rich, or very very dedicated. Or both. Or do they? When Stuxnet finally happened, the general public seemed to believe that APT goes hand in hand with 0-day. A considerable time span passed by, understanding started to sink in, that targeted attacks can have all sorts of faces, and barely any post-Stuxnet attack looked anything like what we now call “the first cyber weapon”.
Until today, analysts seem to have settled for the consciousness that Word Macros are just as dangerous to organizations as the latest Flash exploit. There always is someone to open the damn document.
Finally, what this leaves us with is a set of uncertainties. How important are exploits in the APT world? How frequently are they used, how common is the use of precious 0-days? This is the fog we meant to shed some light on.
Exploit prevalence at a glance
In the mass malware scenery, the number of malware strains and infection campaigns that make active use of exploits is rather low, it feels, and seemingly even declined; at least since attackers found out that Macro downloaders do the job just as well. It won’t fail the attentive reader; Word Macros are a lot easier to write and cheaper to get hold of. And back here we are, reducing the cost of an attack allows to maximize the number of potential targets. It’s all about resources.
But let us get to the numbers. In total, we analyzed 326 events within our final analysis set, of which 54 were labeled to involve one or more exploits. Such labels are usually tags of CVE numbers that are added by the initial reporter of an event. About these tags we do know, that a present tag is a strong indicator for an actual exploit being involved (given analysts didn’t make things up); the lack of any tag does not proof at all though that no exploits were used. As a counter metric, we utilized detection names of Microsoft Defender, filtering for names containing one or another CVE number. This way we detected a total of 68 events involving exploits.
Juggling numbers, with considerations of potentially missed detections in mind, roughly a fifth of the analyzed events involved the usage of exploits. With all potential data incorrectness in mind, we are very confident to state that is it not a majority of targeted attacks that involves exploits.
The APT exploit landscape
Relying on tags that are present in the MISP data set, we went on to evaluate the exploits we indeed did see. The graphic below shows a chart of CVE numbers, sorted first by tag counts, secondly by year. The numbers refer to the number of events that make use of the listed CVEs.
It is worth mentioning, that human analysts as well as security software tend to be more reliable in labelling of well-known exploits, than fresh ones or even unknown ones. This chart cannot be used to determine which attacks involved 0-day exploits; in fact, none of the data we got at hand can.
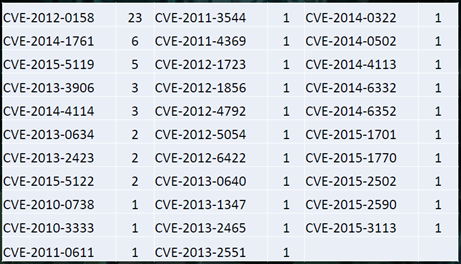
What it does show though is how the curve from frequently to non-frequently seen CVEs holds remarkably old vulnerabilities in the top spots. Absolutely killing it is CVE-2012-0158, a vulnerability within an MS Office OCX library. It can be triggered through a malicious Word document. The vulnerability has long been fixed by Microsoft, but, perhaps, not all Office installations are updated all that frequently? Who knows.
Furthermore, we can see that only a minority of 7 CVE numbers can be called more or less up to date. Given that our data collection ended January 2016, vulnerabilities from 2015 are considered fresh (enough). A total of 12 events involved exploits for non-cyber-stoneage vulnerabilities.
Exceptionally interesting is place number three on the list, CVE-2015-5119, sported by a total of five events. This vulnerability has a history, indeed.
HackingTeam exploit gone wild
CVE-2015-5119 is a vulnerability in Adobe Flash, which got leaked with the tremendous breach of the Italian offensive security company HackingTeam last year. The vulnerability was reported and fixed soon after the breach, but nevertheless made it into at least one exploit pack and the toolsets of four quite well known APT groups. According to our data, Group Wekby and a not closer identified spearphishing campaign targeting US government institutions adopted respective exploits right after the breach went public, in July 2015.
The most recent spotting of CVE-2015-5119 within our data happened beginning of 2016 when it was seen in context with BlackEnergy, the notorious malware that took the Ukrainian power grid offline end of 2015.

Discussing the results
The numbers in the dark, or, everything we do not know, is a significant blind spot to our dataset. There are two considerable unknowns. For one, we do not know whether the data is complete. Two, we do not know whether the labels we retrieved are correct.
Concerning problem number 1, intentionally incomplete reports aside, it is very well possible that an attack is detected and remediated, but the actual infection vector never recovered. In the case of an exploit being used, given for example that it is not contained in an e-mail or a file, the forensic reconstruction of the entire intrusion path can be challenging. A good example of such a case and also a very instructive read on the topic poses Phineas Fisher’s write up of the HackingTeam breach.
Problem number 2, incorrect labeling, stems from the fact that determining a CVE number for an actual exploit involves careful analysis work of a specialist. In practice, deriving CVE numbers from AV detection names is “cheap” and works reasonably well, but relies on the respective analysts doing a scrupulous job when looking into the sample. Nevertheless, mistakes are actually quite possible.
As in all given cases, I am happy to receive suggestions on how to improve on both shortcomings. Meanwhile, we present the discussed numbers with a pinch of salt on the side.

You must be logged in to post a comment.