
Welcome back, to the fifth and last part of our blog series The Kings In Your Castle, where we aim to shed light on how A.P.T. functions, how targeted malware looks like and the issues us analysts might find on it. If you are interested on how it started, please check out the parts 1, 2, 3 and 4; namely here, here, here and here.
In part 5 now I will describe how we leveraged our gathered data for correlations, to unveil connections among targeted attacks, reported to CIRCL’s MISP instance. Furthermore, this blog looks ahead on what happened after the presentation of our proof of concept at this year’s Troopers conference in Heidelberg. Large parts of the parsing and correlation functionality has made its way into the code base of MISP. Raphael Vinot has published the MISP Workbench, where MISP users can now perform their own correlation of events found in MISP.
Corre…what?
For starters, let’s define the term “correlation”. We define this as the uncovering of links of any kind among events reported to MISP. A requirement for reports that support a correlation is that they refer to one single event which goes beyond the general information already contained in MISP. Through this correlation we can glean extended knowledge of a toolset used by an actor as well as information on target preference. We also get to know about shared tools or techniques among two or more actors. We would also count it as a successful correlation if we find proof that two supposedly related events do not share any links at all.
A big step from classical (mass-)malware detection to research and mitigation of targeted attacks was, to recognize a pattern over time. The fundamental difference between targeted and non-targeted threats is that non-targeted threats does not know and/or care about their target. While campaigns of non-targeted threats also tend to improve over time, targeted actors have a significantly more developed need to stay ahead of their victims. This way, when tracking threat actors, one might spot new additions to their toolset, new intrusion techniques or even see them picking up new “business lines”.
Also, looking at malware campaigns from a historical perspective helps uncovering false flags as well as attempts to cover their tracks. This is especially significant when looking at how actors learned to do this over time.
With all of this reasoning in mind we dug through data sets with (and, occasionally, without) structured approaches, in order to unveil hidden treasures.
Naming is hard
And frequently, when uncovering supposably unknown links among different events, we found ourselves poking at the very same group of aggressors; using the very same malware and attack methods as the linked event would show. But how come?
There are several reasons to this, the most obvious one being that two events were reported, commenting on differently named groups, but actually referring to the same. This is an old issue in threat analytics; naming is hard. The reality was that in most common cases we quickly realized that each time we had a link, we were looking at identical events that were just named differently.
Probably the most popular case of multi-naming is Havex; otherwise known as EnergeticBear, DragonFly, or CrouchingYeti. This group has been mentioned in at least four different reports, with dedicated naming on all four. Similar cases have been observed for Sakula, also called BlackVine, and for WhiteElephant, also called Seven Pointed Dagger.

What we found
The purpose of correlating different events was to try and find any existing links between events that were either instigated by different actors and/or performed at different points in time by the same group. For one, we wanted to proof that we could uncover links among sample sets and groups with little technical effort. For instance, we were able to spot a spear phishing attack within MISP which clearly related to other campaigns driven by an actor known as APT1. APT1 is said to be a Chinese group, performing a plentitude of attacks in (years?). It is hugely beneficial to have advance knowledge of past attacks and current changes to an attacker’s toolset. This is especially true if an attack by a specific group against a given target may be imminent or already in progress.
What turned out interesting also though, was uncovering events documenting the same group, but extending the view to include the capabilities which were added over time. One example for this is TurboCampaign. This was first reported in 2014. By that time it went by the name of Shell_Crew. When spotted again in 2015, they sported a 64-bit Derusbi implant for Linux machines, which had not been observed earlier. It is unclear at this point, whether this component was just missed in the 2014 report or if it was added less than a year later. The fact that attack groups learn as they go and extend their toolset is not surprising. This learning process gives us exactly the kind of information we set out to learn.
Other things we found in similar ways were for example a link between a report on The Dukes and another campaign dubbed Hammertoss; we linked an RTF spearphishing campaign from 2014 to the PittyTiger group, and we discovered a connection between RedOctober and the Inception Framework.
How to determine what’s related
We should underline again that what we did was not yet another machine learning exercise. The attributes outlined in previous episodes of this series can potentially serve in malware machine learning research, but exploring this was out of scope for what we had in mind. But what DID we do then?
We followed a rather simple approach. The set of indicators mentioned in blogpost #2, combined with attributes already present within MISP, went into a Redis backend, hosted on strong computing power. Redis allows, to perfom rather quick queries on large datasets in memory. By calculating hashes to index data items, large sets can be processed from different angles.
This way we can perform correlation runs based on IP addresses, domain names and file hashes, as well as compilation timestamps, original file names, import table and ssdeep hashes and many more. As outlined mentioned last time, targeted malware is likely to not be packed or obfuscated. It is also likely to be reused, either in its compiled form or only parts of its source code.
The following graphic illustrates a snapshot of data, related to one event within MISP. One can quickly identify certain patterns, as well as absent data. Naturally, PE-specific attributes can only be retrieved from Windows PE binaries. Help on that front is provided by ssdeep hashes, which also serve for file clustering approaches.
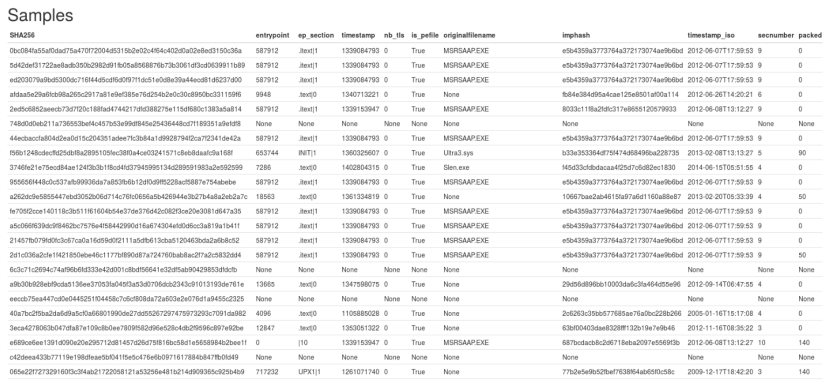
Ssdeep clustering
Ssdeep, apart from computing a piece-wise hash of a given file or data blob, is capable of measuring the distance between two or among multiple ssdeep hashes. These distances are named match scores, weighed measures of how similar two given files are to each other. This is possible because of the fact that ssdeep does not calculate cryptographical hashes, which identify the entire file, but only pieces of a file. Those can then be compared to the piecewise hash of a different file. Naturally, this method can be extended to compare multiple files to one file, and also looking into groups of files, calculating distances among all of those.
This principle allows for clustering of files, based on ssdeep hashes. The most popular implementation of ssdeep clustering, and also the one we based our toolchain on, is ssdc by Brian Wallace. As extension to the original implementation of ssdc, we added a multi-process computation module and a Redis connector, to be able to store clustering results directly to the backend.
This way we are able to spot events which are “close” to each other based on similarities within the involved binaries. With this information one could, for instance, establish that a group targeting entities within Russia, is using malware which bears disturbing similarities to malware used by a (different..?) group targeting entities within Afghanistan and Tajikistan. Just saying….
Ssdeep clustering challenges
Processing fuzzy hashes is a very resource intensive task, even more so when clustering samples of them. This doesn’t scale well for sample sets of certain sizes. Our test set is limited, but given that most malware repositories deal with a sample size within the hundred thousands or bigger, some presorting of groups of interest might be feasible. This pre-sorting of samples which match a certain set of criteria (e.g. events of within a specific timeframe, targeted platforms only geographical constraints) can speed up the clustering approach significantly.
Lastly, it’s worth mentioning that ssdeep hashes, just like any other statically retrieved attribute, only help describing the outer surface of a sample. It does not carry information about the purpose or behavior of a binary and is easily disturbed by runtime packers and might even fail its purpose after malware authors apply a simple change in their compiler settings.
Taking things further: MISP Workbench
Please note that, by now, this kind of APT research has been performed by designated threat research teams for a long time and presented techniques are not considered new. The community benefit we see here is the integration of our toolset into MISP’s open source code body, as well as providing results and conclusions to the broader public. Research of targeted attacks is difficult without access to a large malware set and high quality threat intelligence data.
So now here we are. With MISP Workbench the tools we developed and the data we gathered were integrated into the MISP platform in order to support incident responders and researchers to easily perform their own queries when investigating one or more events.
Workbench was built with the objective to incorporate all the presented features into one single tool. Also, it is intended to enhance the existing MISP dataset with a rich feature set, especially regarding the presented PE features. Workbench can now be used to easily group events by attacker tool sets; in connection with MISP Galaxy this is also possible with focus on dedicated adversaries. Workbench supports full text indexing and lookups for keywords, as well as picking through events on singular features or indicators.
Fine folks at CIRCL have built Workbench for standalone use, with a lightweight user interface. A more detailed description can be found here.
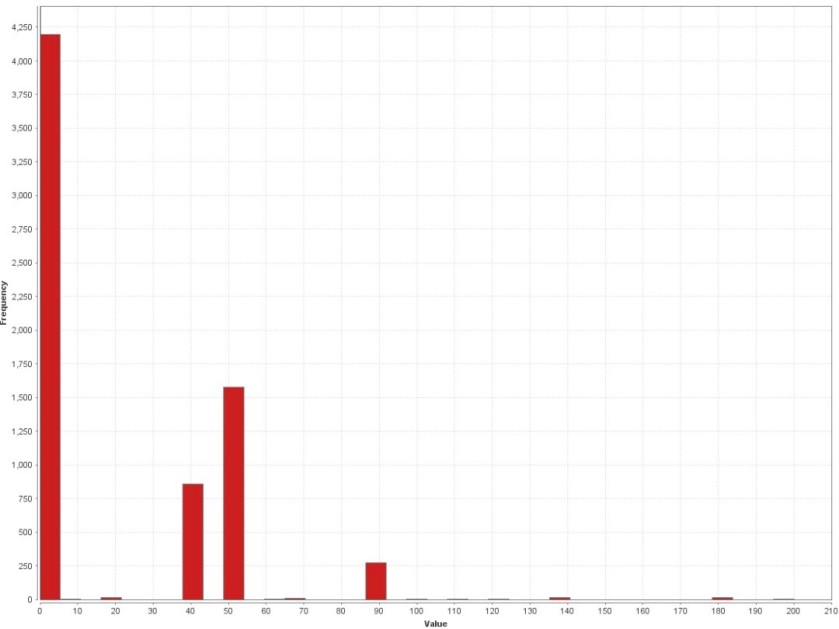
The following screenshot shows statistics about binary compilation timestamps within our targeted malware test set. One can quickly see, how 1970 and 1992 must have been very busy years for lots of malware authors. Err… kidding, of course. But it does seem obvious how compilation timestamps, or even just parts of compilation timestamps, can occasionally serve as an interesting grouping attribute.

Furthermore, Workbench in combination with Galaxy, supplies information about threat actors and events linked to them. This enables the analyst to search for links among threat actors on a binary feature level.

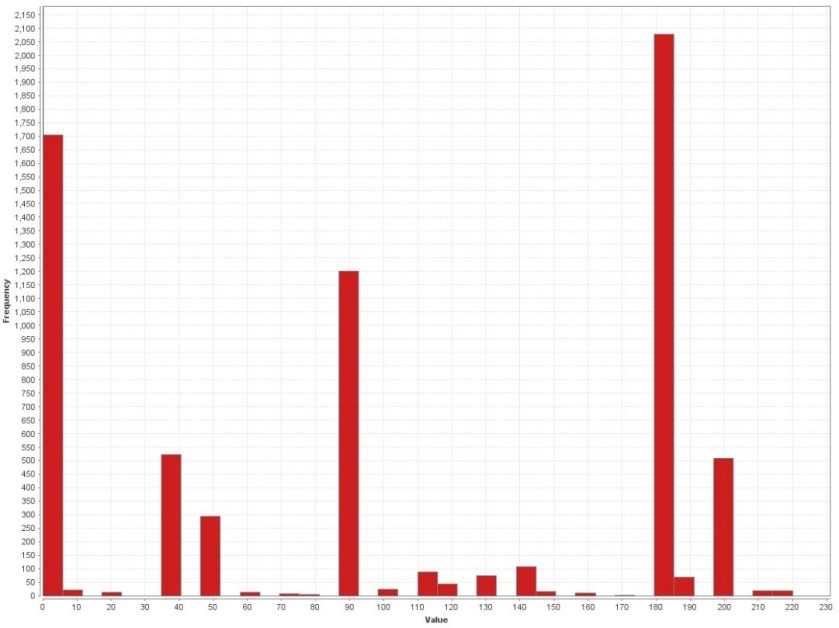
As mentioned, the extracted PE features can be used for grouping as well. The following screenshot shows how the filename ‘chrome.exe’ seems to be an all-time favorite of The Dukes, a threat actor operating out of Russia.

Finally
And here it ends, this lengthy blog series on Kings In Your Castle. The work will continue, of course. The tools presented, just as any information sharing platform such as MISP, live from the collective effort of contribution to the tool stack, the threat information base and the distribution chain. In that sense, questions and comments are welcome, just like pull requests, bug reports and feature ideas. At this point let me say thank you once more, to my co-sufferer Raphael Vinot, as well as the team at CIRCL, the team at ERNW and Troopers conference for letting us present our work as well as Morgan Marquis-Boire for supplying samples and ever more samples.
Happy APT hunting everyone 🙂





You must be logged in to post a comment.