
Automatically finding SMT covert channels
Introduction
In my last blog post I found two covert channels in my Broadwell CPU. This blog post will again be about covert channels. For those unfamiliar a covert channel is a side channel where the attacker has an implant in the victim context and uses his channel to “smuggle information” in and out of the victim context across existing security boundaries.
In this blog post I’ll explore how we can automate finding SMT covert channels. SMT is intel speak for hyper threading.
Before I proceed I should note that one of the two covert channels I found in my last blog passed, the one based on the RdSeed instruction, appears also to have been found by others. You can read about it in D. Evtyushkin & D. Ponomarev [1]. They will be presenting their work on this channel at CCS. Unlike myself they develop the channel fully and discuss mitigations. So if you find this channel interesting their paper is well worth a read.
SMT and side channels
For a long time, I’ve wanted to look for side channels in SMT. SMT is the technical name for hyper threading. Back in Pentium 4 Intel figured that most stuff that goes on in a CPU core is used relatively seldom, so they had the idea that you could run two hardware threads in the same core if you duplicate only the most important subsystems of the core. The remaining subsystems would be shared between the two hardware threads. In the event that the two threads simultaneously want to use a shared subsystem, one would just have to wait. In short you gain significant amount of performance, for a little bit of infrastructure. The problem is if you read what I just wrote sideways, it got “side channel” stamped all over it. In fact, there has been a number of example of side channels related to SMT found in the past. For instance, Acıiçmez and J.-P. Seifert [2], D’Antoine [3] and my last blog post had neat little SMT side channel in the pause instruction – just to mention a few.
Covert Shotgun
The pause side channel I found by reading the intel optimization manual. This is the kind of work one usually do to find these critters. Sort of like a sniper looking for targets. But I figured it might be possible to automate the process – more like shooting a shotgun and hope you hit something. Hence my tool for doing so Is called covert shotgun.
The basic idea is if you have 3 instructions. One that you measure the latency of and two which you use to send a signal. The instruction where you measure the latency I call the receiver instruction. Of the two signal instructions one must use a subsystem that is not used by the receiver instruction, whereas the others should not. The receiver’s instructions latency will tend to be smaller when subsystems aren’t shared and we can encode this smaller latency as a 0 bit. To automated the process shotgun picks 3 instructions from a list of interesting instructions, measures latency on receiver instruction while running the two signal instructions respectively.
To implement this, I use the keystone assembler engine to generate receiver and signal code. The signal code is optimized to maximize pressure on any subsystem used by signal instruction:
A: <signal_instruction> <signal_instruction> <signal_instruction> <signal_instruction> <signal_instruction> Jmp A:
I repeat the instruction 5 times to minimize the effects of the jmp instruction. The receiver instructions latency is measured like this:
Cpuid Mfence Rdtscp Mov rdi, rax <receiver instruction> rdtscp sub rax, rdi ret
With a list of instructions, I can pick a receiver instruction and two signal instructions and test the receiver with both signals. If there is a significant difference, I have a manifestation of a covert channel. Covert shotgun uses plain brute force on the list which makes it really slow and stupid (N2 tests) – but for small lists works well enough.
As for what makes out a significant difference my initial idea was to do a classic P-test on 1.000.000 time samples to determine if there was statistical evidence to conclude there was a channel. This turned up side channels that probably really does exists, but would be thoroughly impractical due to noise. The modified check is an average timing difference of at least 1 clock cycle or 1 standard deviation whichever is larger. Where I estimate the standard deviation the square root of the sum of the sample variance of the two. This insures should insure that the channel is practical. I acknowledge that the standard deviation estimator isn’t “blue”, but given the ad hoc nature of “practicality measure” it is not an issue.
Now the smart reader would’ve noticed I used the wording “manifestation of a covert channel”. I generally tend to only count something as a separate side channel if the system where the contention is caused is unique. With this method method we are likely to find several manifestations of the same side channel. However, it’s worth noting that different manifestations might have different properties and consequently any manifestation could turn out to be useful. For example, flush+reload and flush+flush would under this definition be the same side channel. But Flush+Flush is faster and is more stealthy than flush+reload. See my previous blog post on cache side channel attacks [4] and Gruss et al [5] on flush+flush.
Also worth noting is that cover shotgun will only find side channels of the instruction timing type, and only when the instruction parameters are inconsequential. Finding a side channel like flush+reload or even flush+flush is not possible in this fashion.
Strictly speaking cover shotgun can find covert channels cross core. The reality of it is that cross core covert channels of the instruction timing type is rare. I’ve only found the RdSeed channel so far.
The hardware
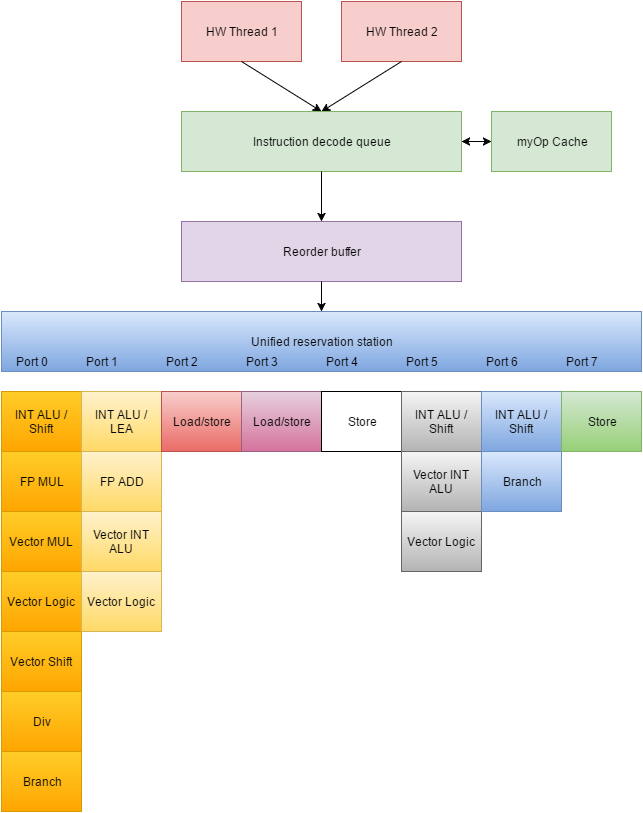
A priori I expect a significant amount of covert channels. To understand my a priori expectation let’s spend a second reviewing some hardware design. Below is a very simplified “map” of the instruction execution logic in my Broadwell intel cpu’ Specifically, I’ve tried to simplify by remove the memory subsystems from the diagram as covert shotgun currently is not usable to analyze this subsystem. Further I’ve sanitized the registers away for simplicity as they are not important for covert shotgun to the extent that registers are duplicated for the two threads.
The first step in execution is parsing instructions into myOp. There is a cache for myOp instructions which could probably be used for cache side channels – if I recall correctly I saw a paper on it. Covert shotgun currently only uses a handful of instructions at once and thus is unlikely to be able to find side channels in this cache. The cache however is particularly interesting as it would give information on instructions in the cache.
Once parsed the myOps are reordered to maximize parallel execution.
The reordered myOPs then enter a queue for the ports. Intel speak for this queue is unified reservation station or sometimes just reservation station. Intel architecture connect individual execution units through these ports.
Each port is capable of handling only one myOp per cycle meaning that it’s fairly easy to run into congestion in the ports. Each of the 8 ports is connected to up to 7 individual execution units which each executes particular specialized tasks. Some execution units are duplicated and available on multiple ports, some execution units are available on only one port – this very well reflects that the CPU was designed for hyper threading. This would lead us to expect to find a high number of manifestations where the receiver instruction and 1-bit sender instruction are identical – with reordering and multiple execution units making sure that it occurs less than 100% of the time. For 0-bit instructions we’d expect a speedup when running parallel with itself. The main point of congestion is probably through the congestion in the individual execution engines – especially those who are not duplicated.
Until Haswell intel had 6 ports and Haswell added an additional 2 ports, going to a total of 8. This allows further parallelization of execution. I think Sky lake added even more ports and duplicated an integer execution unit for better parallelization’s of integer and vector instructions, but I’m not sure. More parallelization typically means less covert channels. These changes should serve as a reminder that the covert channels you find on say a Broadwell, need not exist on a Sandy Bridge and vice versa even when the instructions exist on both. The microarchitecture is subject to change and these changes has significant effects on covert channels and other micro architectural attacks.
Results
Due to the N2 nature of “covert shotgun” I ran a small list of 12 instructions where some were picked because I suspected covert channels in relation to them, and some were chosen because I found the particularly likely to be boring. The list of instructions
| Instruction | My reasoning |
| RdSeed rax | Pretty slow, thus like a “0” signal instruction |
| Pause | The most likely “0” signal instruction |
| Nop | Does it get anymore benign? |
| Xor eax,eax | I used it in my last blog |
| Lea rax,[4*rax+edi+40960];lea rdx,[8*eax+rdi+409623] | I suspected I might get into trouble with the Address generation unit, by using SIB bytes, two instructions and a constant bigger than 2048. |
| RdRand rax | Sounded interesting |
| Add rax,1 | |
| Bts rax,1 | |
| Bt rax,1 | Wanted to check too near identical instructions against each other |
| Cpuid | An interesting instruction on any day |
| Movq xmm1, xmm2 | Streaming instructions must be tested |
| Vtestps ymm1, ymm2 | More streaming instructions…this time 256bit wide |
Running these 12 instructions in brute force meant testing for 936 covert channels. In these I found 521 practical covert channel manifestations. That’s a whooping 55%. Now I expected there to a be a lot of manifestations in there, but this magnitude surprised me. Personally I don’t think the detailed results are that interesting. The thing is that I think SMT in and of it’s own should be considered the side channel here as opposed to considering congestion in subsystem below the SMT as the core reason. However, I will give you a summary of a few interesting finds below.
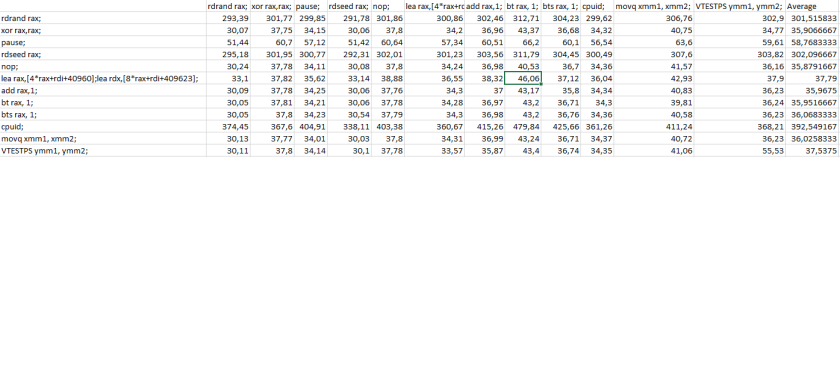
RdSeed turned out to be an extraordinary good “0” signal bit. All instructions run faster in parallel with this instruction than other instructions. No less than 46 of the covert channel manifestation was with RdSeed. With the RdSeed taking around 300 Clk’s to finish, it is likely that this instruction to a very large extend does not interfere with the execution of other instructions, leaving every shared resource mostly free for maximum speed. The pause instruction has the same effect, but not quite as strong and not quite as surprising as RdSeed (Part of the reason for the pause instruction is to yield for the other hw thread). Most likely it’s because the pause instruction has significantly lower latency on my computer and thus more overhead than the RdSeed. If I recall correctly the pause instruction pauses significantly longer on skylake. Interestingly enough the RdSeed instruction also have a significant speedup effect on itself. In my estimation it’s a faster speed up than can be explained with in the pipeline and the most likely reason for the speed up is due to the “seeding unit” being busy and the instruction thus terminating early.
Most of the 1-bit signal instruction instructions does seem to have a high latency when paired with itself than with the average instruction in my test. With the limited number of instructions and the serious selection bias involved I advise against any conclusion.
Unfortunately, I messed up the “lea” test in that I had dependency between the two lea’s and consequently I need to rerun the test. Rerunning the test with lea’s without dependencies did not appear to change the results significantly.
Future research
It would be interesting to run covert shotgun (Preferably made a bit smarter) on much larger lists of instructions to get a much better overview of the situation. Another interesting project would be identifying the subsystem which are being congested by specific instructions. A good starting point would be Agner Fog’s instruction tables[6] and the associated software. This software leverages performance counters to identify port usage and lots of other juicy instruction information.
Further it would be interesting to investigate to what extend these covert channels extend to spying. Especially I found the covariance in instruction timing between different instructions really interesting – there certainly are patterns in there. They suggest that you have congestion on multiple subsystems and perhaps – just perhaps – there is enough data in that to finger print code across SMT. That would be especially interesting say in a SGX scenarios or would lead directly to spying in branched victim code.
A word on microarchitecture timers
Most side channel attacks are timing attacks and thus subject to mitigation through modified timers either by intention or in cases where a hypervisor for other reasons decided to get a VMExit on Rdtsc instructions. For this reason, I’ve been searching for a fast timer that isn’t rdtsc and so far not found one. A natural candidate would be a fast loop synchronized through either overt or covert access. Overt access through memory access was in my experiments too slow to useful. Probably the reason is that a store operation is required that triggers a cache coherency action. So I wanted to see if the RdSeed channel could be used. Unfortunately, the answer is a clear no with RdSeed taking upwards of 200 CLK’s and micro architectural attacks often require accuracy below 70 CLK’s. That said – I have this other idea which I hope I’ll get around to soon
Conclusion
Despite my limited time with covert shotgun it’s has shown great potential. Also I think this simple experiment efficiently shows the dangers of SMT if it wasn’t clear to everybody already. In my opinion it’s justified to talk about SMT being the core cause of all these side channels (and other SMT channels as well) and consequently it’s not very useful to talk about “a pause side chance” as a separate side channel, but as a manifestation of the SMT side channel. With the number of manifestations and different available subsystem the only reasonable mitigation left against these covert channels seems to turn off SMT entirely in threat models that includes attackers having an implant in your VM. Personally I think the root cause is that the attacker is in your VM in the first place. If these methods can be used for spying it is very likely that some can be implemented in java script and thus be used for remote attacks.
[1] Dmitry Evtyushkin, & Dmitry Ponomarev , “Covert Channels through Random Number Generator: Mechanisms, Capacity Estimation and Mitigations”hhttp://ttp://www.cs.binghamton.edu/~dima/ccs16.pdf
[2] O. Acıiçmez and J.-P. Seifert., “ Cheap Hardware Parallelism Implies Cheap Security. Fault Diagnosis and Tolerance in Cryptography” (FDTC’07), pages 80-91, IEEE Computer
Society, 2007.
[3] Sophia M. D’Antoine, “Exploiting processor side channels to enable cross VM Malcious Execution”. http://www.sophia.re/SC/thesis.pdf
[4] Anders Fogh, “Cache side channel attacks”,http://dreamsofastone.blogspot.de/2015/09/cache-side-channel-attacks.html
[5] Daniel Gruss, Clémentine Maurice & Klaus Wagner(2015): “Flush+Flush: A Stealthier Last-Level Cache Attack”, http://arxiv.org/pdf/1511.04594v1.pdf
[6] Fog, Agner, “4. Instruction tables “ http://www.agner.org/optimize/instruction_tables.pdf

You must be logged in to post a comment.