
Welcome back to my series of write-ups for “The Kings In Your Castle – All the lame threats that own you, but will never make you famous”. This series covers a project I presented together with Raphael Vinot from CIRCL Luxembourg at Troopers conference in March. If you missed the start, you can find it here.
O’right lets go 😀
TTPAs – Tools, Techniques, Procedures and Actors
The primary aim in the toolification process was to extract accurate binary features, that would help us describe the binaries in relation to the Event data stored in MISP. Therefor we took the feature extraction a step further than usual IOC creation would (Indicators of Compromise).
IOCs are indicators, which describe malware used in an attack or attributes of an attack. They are easy and comparably quick to create, and then distributed and leveraged to scan computers or networks for compromises. They defer from classical, heuristical malware detection, as indicators are not limited to a per-file basis but can also describe domain names of remote servers, names of files created by malware or IP addresses.
Despite their many advantages though, IOCs trade rather shallow features. Domain names, file names or strings within binaries can be easily changed in the course of an operation and at will of the actor. A goal of our research was to extract more granular file features from different domains than the usual IOCs cover, in a sense, more “expensive” features, that we considered less volatile than domain names. This way we expected to be able to find links among different events contained in MISP, that the usual indicators miss. In a targeted operation, it is considered expensive to change a toolset, rewrite malware or switch infection vectors like for example the purchase of a new exploit. Currently used indicators lack capabilities to describe “expensive metrics”, hence the idea to widen the feature space.
However, extraction of binary features is not at all a trivial task. The technical implementation of feature extraction aside, it lies within the nature of malicious binaries to hide their features as thorough as possible; any features, that is. Runtime packing, obfuscation and sandbox evasion are just a few of many techniques that malware authors use to hinder analysis, which in general difficults feature extraction.
The following lists show attributes that were gathered from MISP, as well as those we extracted from the malicious binaries. The attributes are all gained in a static manner, meaning without the execution of binaries. Sole static analysis is frequently faster than dynamic analysis, the tools more portable and large scale analysis more scalable. Next to that we worked with the hypothesis, that targeted malware frequently comes unpacked and without the use of obfuscation. On the other hand, if an actor decides to rely on runtime packing, it should be an interesting question, whether he decides whether to use a custom packer or a commercial one, and whether samples were individually packed, with a dedicated packer. One would think ‘no’, right?
I will go into more details on the packer-or-no-packer questions in a follow up blogpost. For the time being, I’ll ask you for the benefit of doubt that our test set of binaries supplied us with considerably useful data. Here goes our feature list, fitted with short explanations of the underlying trail of thought.
MISP data
- Event ID
- Event description
- Event Submission date
- CVE numbers associated with malware of given event
- Domains associated with malware of given event
The attributes we pulled out of MISP mainly describe the respective events, which the binary hashes of our set are linked to. This information is highly valuable, as it puts the malware into context. Frequently events in MISP are linked to vendor reports, which provide a plentitude of context for an operation. Furthermore, the event submission date roughly indicates the time when the operation was reported. CVE numbers are considered an indicator, whether the operation involved exploits. This is a rather soft metric, the lack of an entry for a CVE number does not at all proof that no exploits were being used by a given malicious actor. Nonetheless, listed CVE numbers are valuable information.
Sample data
- MD5
- SHA1
- Associated Event ID
- Filetype
- Filesize
- Ssdeep hash
- Detectionname of Microsoft Defender
Sample data is a set of descriptive features, associated with any filetype. In the course of our research we put our main focus on Windows executable files, as these pose the biggest group among the analyzed sample set. Our decision to add detection names from the Microsoft Defender anti-virus solution bases on Microsofts accuracy in assigning names to malware. This knowledge we draw from sole experience, although empirical tests have shown excellent results in the past.
An interesting attribute among this set is the ssdeep hash of a file. Ssdeep is an algorithm, which allows to calculate a fuzzy hash of a given data blob. Fuzzy hashes do not uniquely identify the base data, but are calculated piece-wise. This way ssdeep makes it possible to determine similarities among files, and even draw conclusions about the degree of difference between two given files. For more information about ssdeep and fuzzy hashes please visit the sourceforge website. A drawback of fuzzy hashing is, that the required computing load for comparing similarities among binaries increases considerably with the number of binaries.
Executable data
- Compilation time stamp
- Imphash value
- Entry point address
- Section count
- Original filename
- Section names for sections 1-6
- Section sizes for sections 1-6
- Section entropies for sections 1-6
- Number of TLS sections
- Entry point section
- Count of calls to Windows APIs
- Ratio of API call count to filesize
Finally, for the subset of Windows executable files we collected a wealth of descriptive indicators, which apply to meta-information and the internal structure of compiled binaries. Compilation time stamps of binaries can be easily changed, that is true, therefor they have to be taken with a pinch of salt. Singular cases though have shown, that looking at a campaign over a period of time, following related events on MISP that is, sometimes yields unexpected information “leaks”. This means, actors might follow the habit to falsify timestamps, at the same time though erring is human, and sometimes we encounter binaries with seemingly real time stamps. That said, obviously it is of interest to find attacks related to one specific incident, as historical data can reveal unknown traits of a specific actor.
A number of PE attributes serves the detection of packed binaries. The count of PE sections, section names, sizes and entropy, the count of TLS sections (Thread Local Storage) and the section of entry point for example are considered indicators, whether a runtime packer protects the executable. This is interesting information by itself, as it can be concluded which actors use packed malware, which don’t, and which packing habits the different actors have.
Next to that, the attributes also serve to determine the similarity among binaries. While on unpacked binaries, the attributes are highly dependent on the compiler used to compile the binary, on packed executables the same data shows similarities of the various packers.
Two rather uncommon binary metrics we came up with is the total count of calls to Windows APIs within the code and the API call count to file size ratio. The primary consideration hereby is, that packed or protected executables show little interaction with the Win32 API. Another interest in these metrics though is, that the API calls within a binary relate to the actual binary structure. While code changes or additions within pieces of malware very likely change fuzzy hashes, the imphash, the filesize and section attributes, the changes of the API call scheme should remain considerably small.
Data about the data
The beauty of the data collection process, is that it left us with a set of malicious binaries, that are somewhat guaranteed to have been part of a targeted attack approach at some point in the timeline of their use. Furthermore, with the help of MISP we are able to put the binaries into context, as we know in many cases which campaign they were involved with.
For picking events from MISP we applied a lose set of criteria. MISP’s events are pre-classified by the submitter, where a threat level of medium or high indicates, that this event is likely of a targeted nature. From this group we handpicked events, where the description suggested it deals with a known or at least an identified threat actor, or where the nature of the malware clearly suggested a targeted background; like e.g. themed spear phishing would.
The initial data collection started November 2016, so the total set of events only includes cases submitted to MISP until middle of December 2016. However, in follow-up work some of the feature correlation procedures have been adopted by MISP itself. For more details please refer to the website.
Please note, this procedure leaves quite some room for incorrectness. We assume by default, that indicators reported by vendors and their context are correctly associated. This is not always the case, as we found out while performing tests; in some rare occasions data in vendor reports has turned out to be incorrect. As of now we do not have insight which percentage of reports shows errors. Furthermore, the events contained in MISP only show information that actually is reported, meaning that attacks which by the time of analysis yet have to be discovered as well as attributes which are potentially missing from reports pose a blind spot to our research.
Finally, we started off with a set of 501 events, which we assumed to contain information about targeted attacks, containing a total of 15.347 malware samples. From this set we removed another subset of events, which we determined to be overlapping with another event of the same attacker or incident. Duplicate entries happen, as MISP is not striving for accuracy but for completeness. The cleanup left us with a set of 326 events and 8.927 samples.
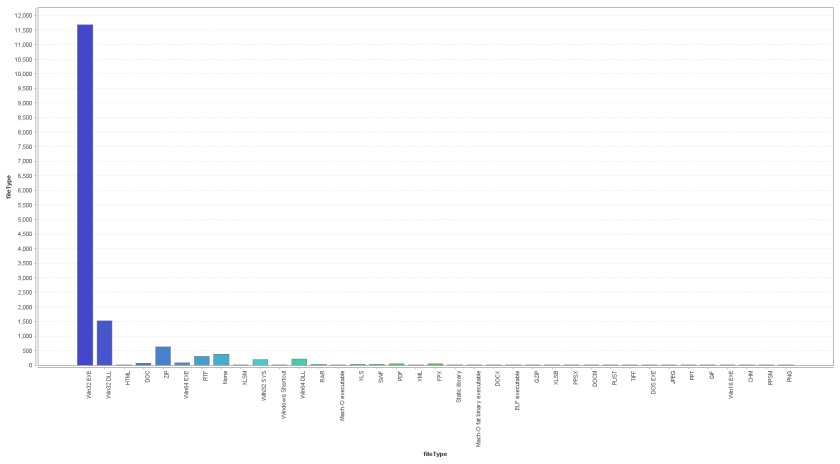
The graphic shows the file types of the entire sample set. It can be seen, that Win32 PE executables are rather dominant. This is explained by the heavy use of repackaged commodity malware by some actors, but does not represent the general distribution of file types per event. Nevertheless, PE32 is the most important file type within the analyzed sample set, counting more than 11.000 out of the total corpus of 15.347 samples.
In the next blogpost I’ll be introducing our results of an exploit-per-APT analysis, and write about one or another curiosity we found within our final data set.



You must be logged in to post a comment.